【记录】服务器使用
SSH连接服务器
通过SSH连接一个账户为user的一个最简单的命令是:
1 | ssh user@***.**.**.** |
其中,@前面的是用户名,一般来讲管理员账户是user,后面是ip地址,这里我就隐去了。注意这里默认了SSH的端口是22。
如果你使用局域网,只需要在服务器上ifconfig一下,得到局域网ip地址(192.168.1.***),进行SSH连接即可;一般我们会做穿透,具体过程不做展开,大致可以理解为租用一个服务器作为映射的跳板。总之会获得一个公网的ip地址和端口号,所以一个更全面的命令是:
1 | ssh -L 29999:127.0.0.1:6006 -p ***** user@***.**.**.** |
这里-L表示本地地址端口号映射,由于tensorboard默认是在6006端口,SSH又没有图形界面,所以我只要在本地浏览器上访问127.0.0.1:29999,就会相当于在服务器上访问127.0.0.1:6006,就可以看到tensorboard的内容了。
-p后面跟的内容是映射后的端口号,这样也会一定程度上减少公网上对于SSH的攻击。
创建新用户
一般地,user用户具有最高权限,只对管理员开放使用;实验室每个人使用都会建立自己的账号,这样互相之间的使用不会冲突。建立的过程大致如下:
1 | sudo useradd -r -m -s /bin/bash fjn |
其中
-r:建立系统账号(这里似乎加不加上都问题不大?)
-m:自动建立用户的登入目录
-s:指定用户登入后所使用的shell,后面参数为路径。我这里就用bash了,也可以使用zsh什么的。
fjn就是用户名啦,下同~
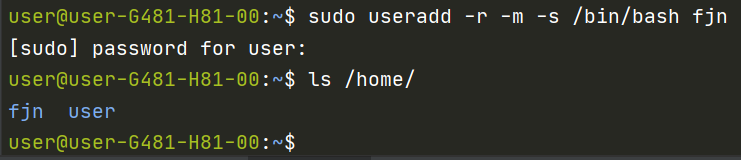
通过ls /home/可以看到已经自动创建了用户文件夹。
修改密码
这个用户创建完之后密码可以认为是随机的,所以如果你直接sudo su fjn的话(这里su的意思是switch user,切换用户),会很尴尬,因为切换过去就切不回来了(再切回来需要新账户的密码),只能原地exit……
所以这里需要进一步修改新用户的密码:
1 | sudo passwd fjn |
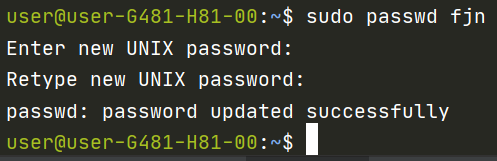
重复输入一遍设定的密码后,便设置完成。公网ip的话尽量还是设置的强一点,不要搞什么1啊123之类的这种很快就会被破译掉,我们实验室以前是出过这种事情的,被人黑进来,kill掉你的所有进程,然后执行挖矿程序……
可惜不太懂挖矿,要不我就把钱包账户改成我自己的了
修改用户权限
就差一步我们就要大功告成啦,我们还要赋予新用户一些权限。如果不做这个操作的话,新用户是无法使用sudo命令的。也就是说sudo apt install之类的命令我们都用不了,那肯定是不行的。
sudo的权限控制被设置在/etc/sudoers这个文件中。网上许多野鸡博客都会让你对这个文件chmod,这些虽然在结果上也会达到效果,但是多少有些野鸡,因为如果你sudo vi /etc/sudoers的话,它在一开头就赫然写着:
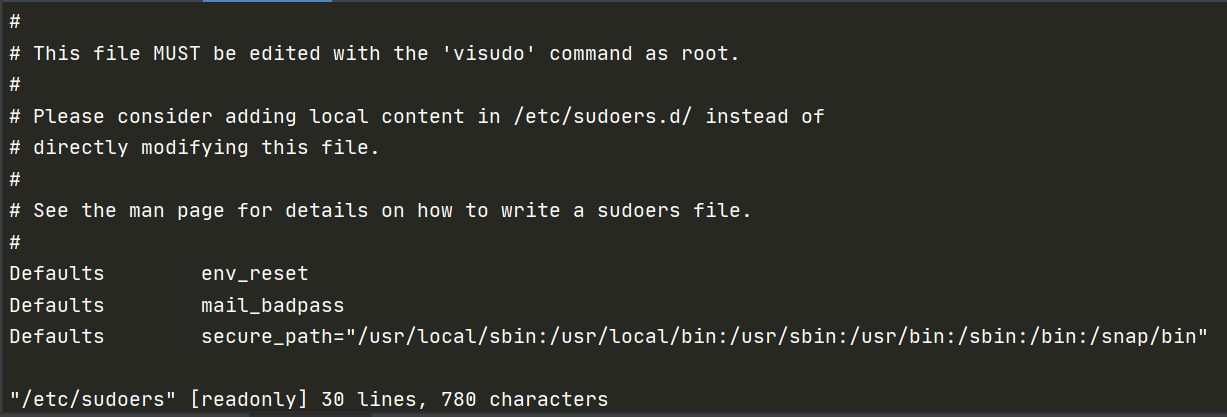
This file MUST be edited with the ‘visudo’ command as root.
就算你要用vi,文件也建议了你去修改/etc/sudoers.d这个文件。所以正确的做法应该是,先切换到root用户:
1 | sudo su |
然后通过visudo命令进行修改,顾名思义就是修改sudo权限组嘛:
1 | visudo |
此时会以一个特殊的界面进入sudoers文件中,然后就可以对应的修改了。找到
# User privilege specification
这一项,在root下面对应地照抄,把root改成用户名即可,如图所示:
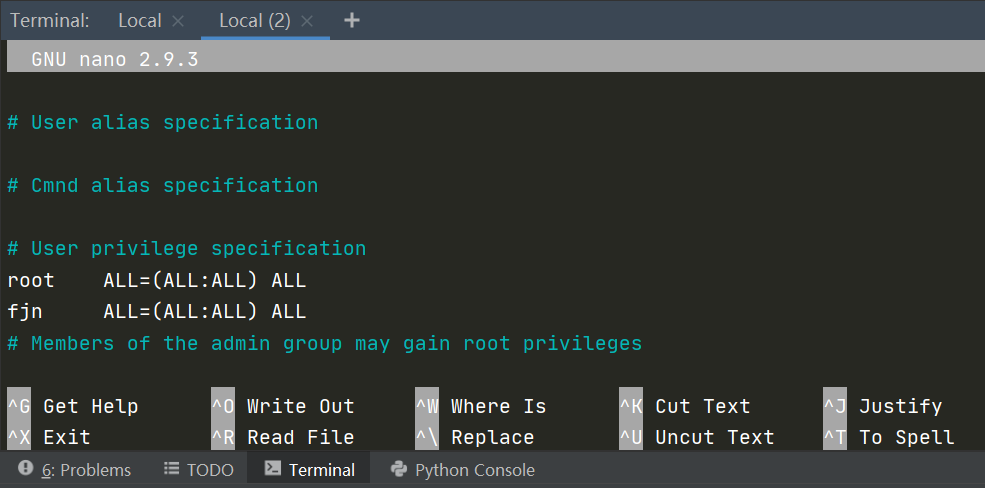
完成后按X退出,随后其会询问”Save modified buffer?”,这时按y;然后又会询问文件存储地址,这时候直接回车就好了。
此时,便可以输入exit退出重新连接了。
重新登陆
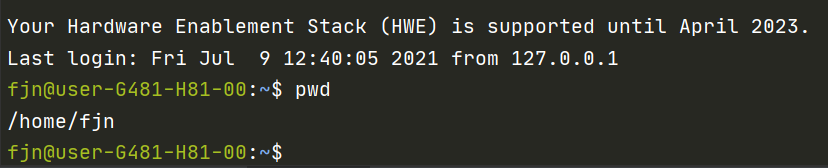
配置完毕后便可以用自己的账号登陆了(注意用户名处变更):
1 | ssh -L 29999:127.0.0.1:6006 -p ***** fjn@***.**.**.** |
再输入pwd即可看到当前绝对路径地址,系统已经自动为你建好了用户路径:
Anaconda的使用
安装Anaconda
Anaconda是一个很好的包管理软件。其软件安装包可以在清华大学开源软件镜像站找到,所给链接已经将之按时间降序排列。
我们可以在本地主机上访问镜像站,获取链接后再在服务器上wget下载。这里找到适合自己服务器架构的安装包,一般来讲是Linux x86_64之类的
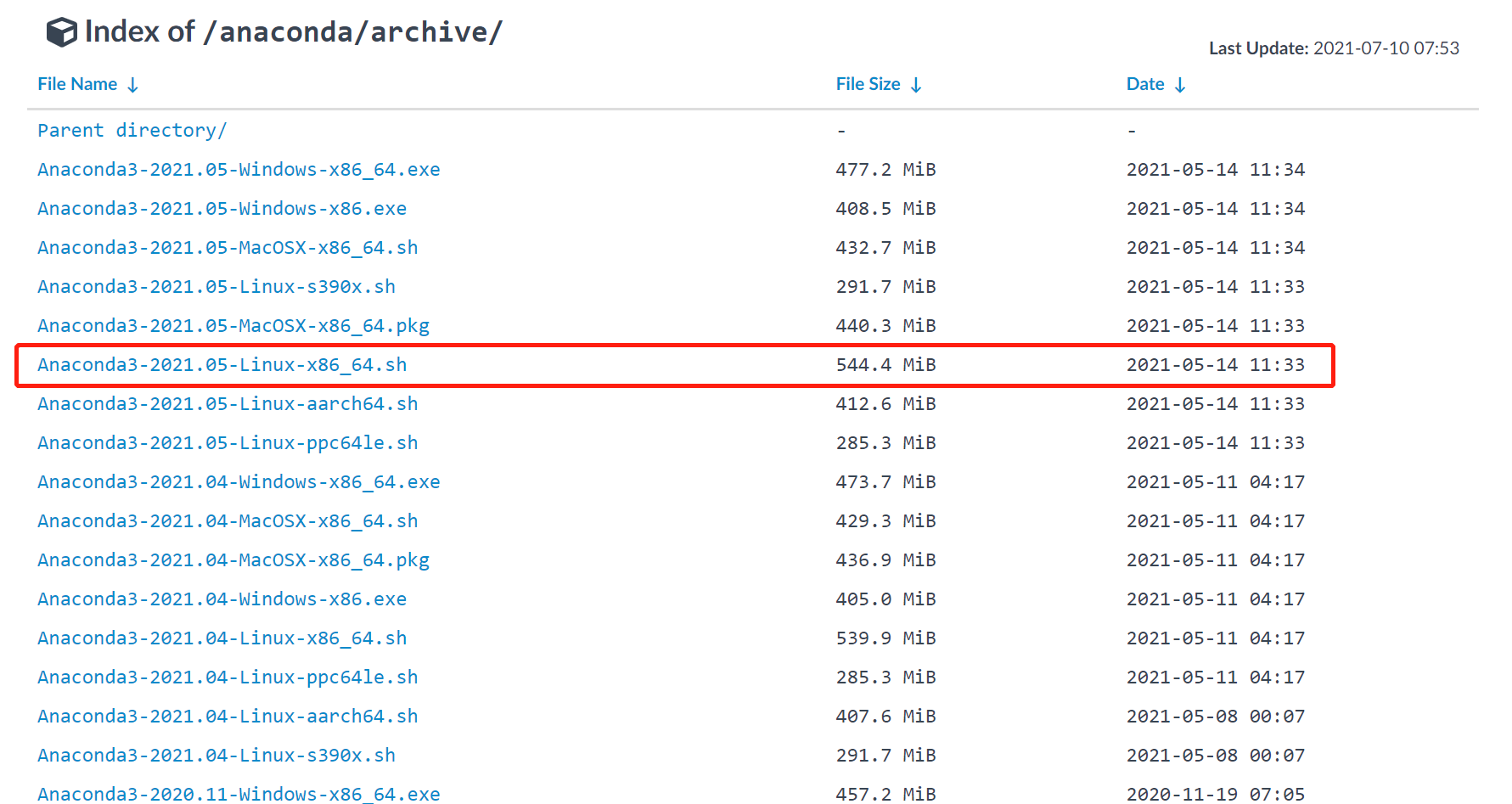
右键复制链接地址后,在服务器中wget,比如我这里是2021.05的版本,如不介意最新版本也可以直接复制粘贴以下链接:
1 | wget https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/Anaconda3-2021.05-Linux-x86_64.sh |
然后就是bash安装的过程了,大致就是(注意可以tab补全):
1 | bash Anaconda3-2021.05-Linux-x86_64.sh |
长按Enter(阅读条款)→yes(同意条款)→Enter(默认路径即可)→yes(要conda init)
初次使用的话要(在~的路径下)source一下就可以了:
1 | source .bashrc |
增加channel
我感觉这一点很多朋友都不太清楚。我们知道,conda search可以查询一些包的版本情况,比如我们查询tensorflow-gpu的版本情况:
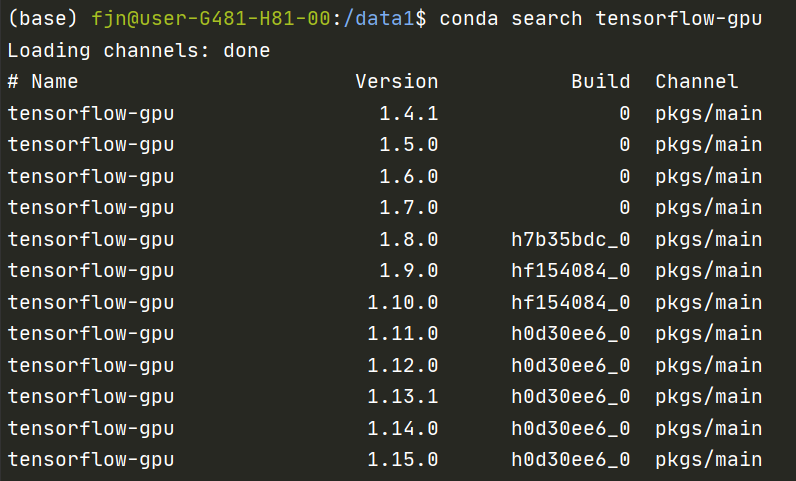
可以看到,这里其实是没有1.2,1.3之类的版本的,但很多repo当中确实是使用的这几个版本,这时就需要设置更多的channel了。通过这个命令可以查询当前的通道都有哪些:
1 | conda config --show channels |
一般来讲,只会显示默认的defaults。按照网上的推荐,大家可以添加以下两个channel,基本上够用了(main有时候会挂掉,可以先只添加free的),如果有兴趣也可以查询更多的channel。
1 | conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ |
添加完成后,可以再输入conda config --show channels以明确添加了以上通道。再进行搜索,可以看到有了更多的tensorflow-gpu版本:
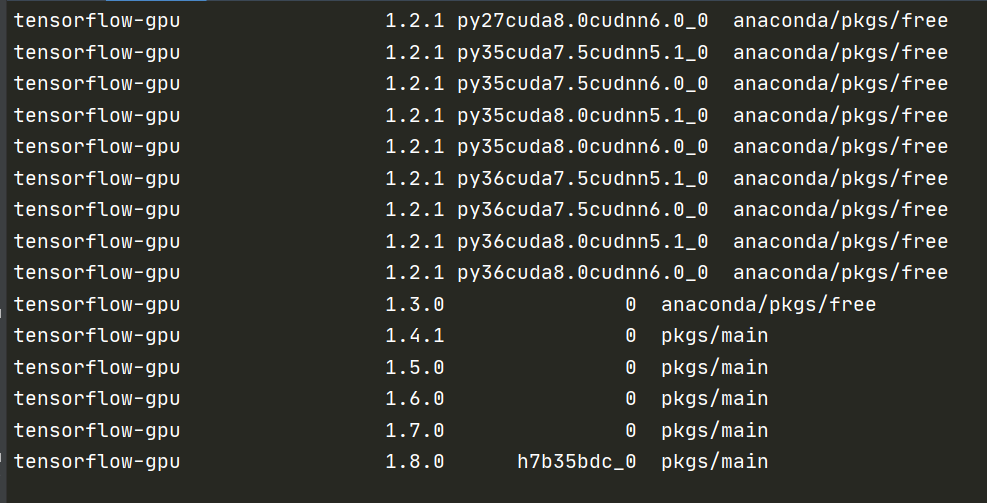
总之,添加完成后,首先该搜到的包都还搜得到,原来搜不到的可能也会搜得到,也增加了anaconda服务器挂掉 (特殊时期) 时候的鲁棒性。
如果出现HTTP error时也可以通过将add改为remove的命令删除通道。
bypy的使用
由于没有图形界面,所以下数据集的话会有一点麻烦(除非你找到国内的镜像源地址),而如果使用scp命令传文件的话基本只有2、3M/s,会成为带宽瓶颈,这时就可以使用百度网盘这个神器,我这里大概是10M/s左右的速度。
当然了,这得益于我有在百度网盘中收集储存数据集的习惯(实验室比较惨没有NAS,也没个ftp),如果没有这儿习惯的话,再增加一步上传操作时间就会增加,可能直接scp一步到位会是更好些的选择吧。
关联账户
初次使用请先安装(可以在conda环境的base中):
1 | pip3 install bypy |
认证信息:
1 | bypy info |
然后terminal中会给出一个网址链接,这个链接,我们在登陆了要绑定的百度网盘网页中打开它,就会得到一串验证码,我们需要把这个验证码复制回terminal中,以完成绑定,如下所示:
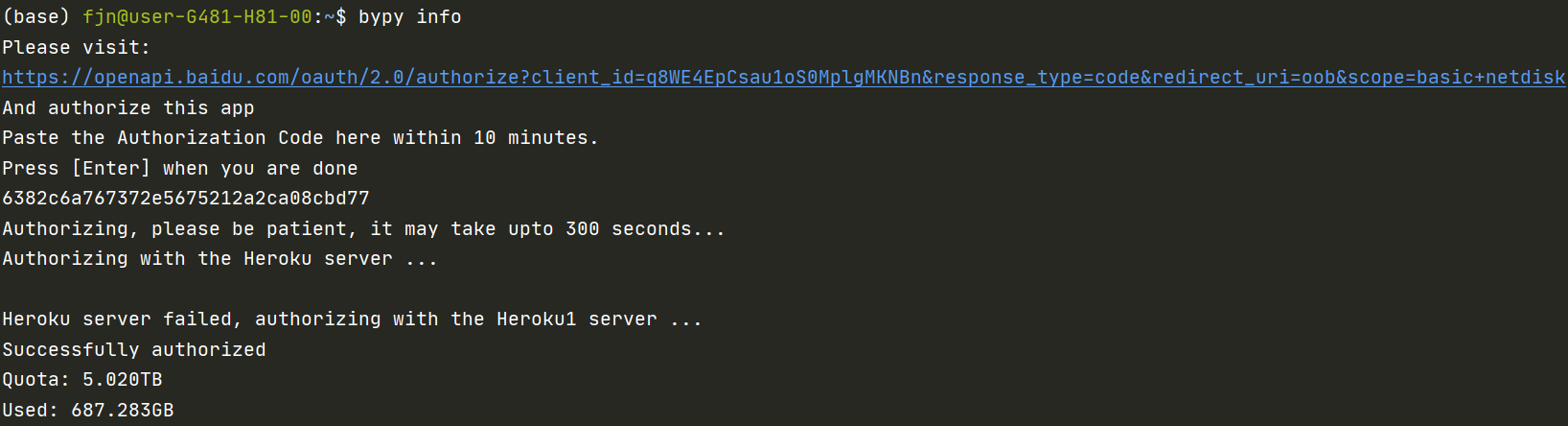
这个认证会随网络情况波动,可能很快也可能很久,我都经历过。认证成功后会显示Quota和Used。
然后你就会看到百度网盘里面出现了一个文件夹叫“我的应用数据”,然后里面有一个文件夹叫“bypy”,而这被视为是bypy的根路径,比如你在这个文件夹里有一个文件x,我们想要操作这个文件的话路径就直接是x。
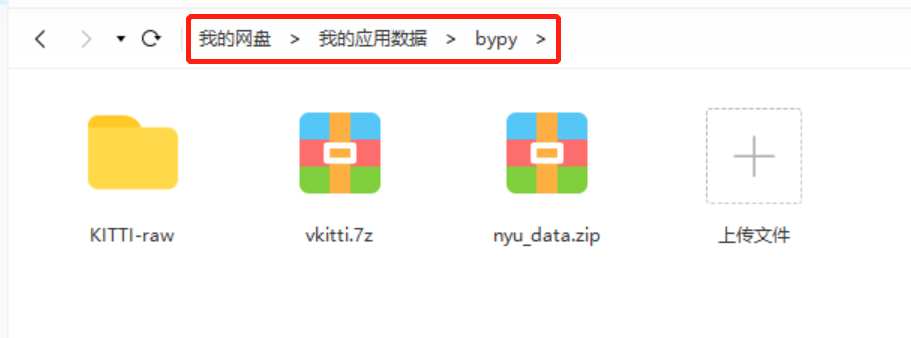
比较蛋疼的是,我试了上级路径(../)似乎是失效的,所以可能需要把要交互的文件夹都放在bypy这个文件夹下才行。
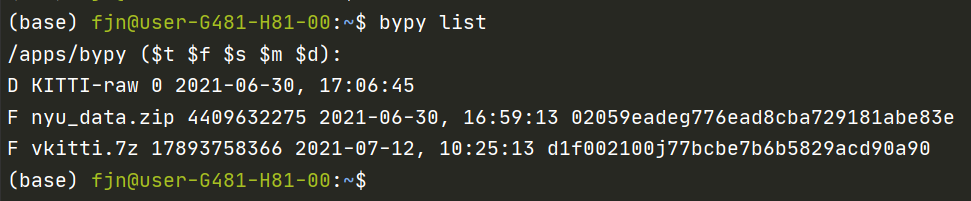
通过bypy list可以看到当前路径下的文件情况,D表示目录(directory?),F表示文件(file?),比如刚刚截图中的文件情况就会被反映成下面这样:
1 | bypy list |
文件交互
使用downfile下载单个文件;
使用downdir下载文件夹;
使用upload上传文件/文件夹;
关于这些交互命令的使用,其实可以直接bypy --help来获取更多信息。
所以我在这里举个栗子就都懂了。比如我要下载vkitti.7z这个文件,命令就应该是:
1 | bypy downfile vkitti.7z |
比如需要下载KITTI-raw这个文件夹,那就是:
1 | bypy downdir KITTI-raw |
似乎这两个命令都可以被download一个替代,有好事者可以测试一下;
上传的话一般用不到,我能想到的使用场景就是传输一些pth文件。你可以选择在命令中指明文件,如果不指明则默认上传当前目录下全部文件,例如:
1 | bypy upload (xxx) |
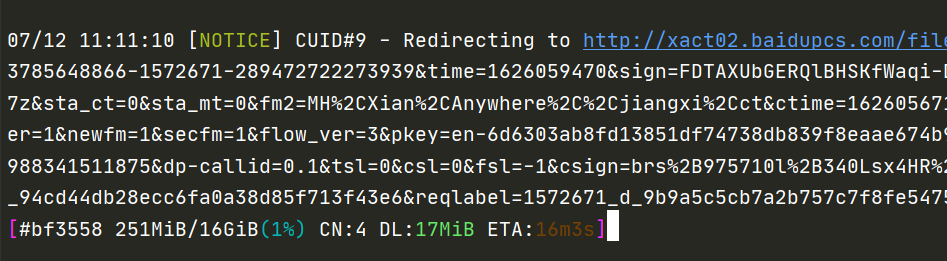
划重点:--downloader这个参数非常有用,使用aria2之类的下载器可以飚到很高的速度,所以一般来讲命令如下:
1 | bypy --downloader aria2 downfile vkitti.7z |
不过需要提前安装下载器:
1 | sudo apt install aria2 |
这回测试,速度居然可以飙到17M/s,不过平均来讲速度基本在10M左右,已经很不错了,一个16G的数据集大概20分钟左右就能下完了。